
Tue 10-vuotiasta Faktabaaria #TueFaktabaaria
-
 23.04.2024 FI
23.04.2024 FIVinkkejä tekoälyn tuottaman sisällön tunnistamiseen
23.04.2024 FI -
 22.04.2024 FI
22.04.2024 FIITK-konferenssissa opettajia kiinnosti tekoäly – Faktabaari muistutti, että hyvässä autossa oltava hyvät jarrut
22.04.2024 FI -
 15.04.2024 FI
15.04.2024 FIFaktabaari mukana ITK-konferenssissa – tutustu kattaukseen!
15.04.2024 FI

23.04.2024
FI
Vinkkejä tekoälyn tuottaman sisällön tunnistamiseen
23.04.2024
FI

22.04.2024
FI
ITK-konferenssissa opettajia kiinnosti tekoäly – Faktabaari muistutti, että hyvässä autossa oltava hyvät jarrut
22.04.2024
FI

15.04.2024
FI
Faktabaari mukana ITK-konferenssissa – tutustu kattaukseen!
15.04.2024
FI

10.04.2024
FI
Mikko Alasaarelan verkkoluento: Tiktok & somealgoritmit (katsottavissa 17.4. saakka)
10.04.2024
FI

10.04.2024
Faktantarkistus
Venäjän propagandaa levittävä Portal Kombat -verkosto avasi suomenkielisen “uutissivuston”
10.04.2024
Faktantarkistus

08.04.2024
FI
Tutkijat: Suomalainen media luottaa ehkä liikaakin kykyynsä tunnistaa disinformaatiota
08.04.2024
FI
FAKTANTARKISTUKSET
Faktantarkistuksissa noudatetaan Faktabaarin toimitusperiaatteita sekä Journalistin ohjeita. Tarvittaviin taitoihin voi tutustua EDU-sivuilla.
10.04.2024
Faktantarkistus
Venäjän propagandaa levittävä Portal Kombat -verkosto avasi suomenkielisen “uutissivuston”
10.04.2024
Faktantarkistus

18.03.2024
Faktantarkistus
EDMO-selvitys: Julija Navalnajan julkisuuskuvaa yritetään Euroopassa murentaa disinformaatiolla – ja syväväärennöksillä
18.03.2024
Faktantarkistus

13.03.2024
Digivaalivahti
Faktabaarin ja CheckFirstin selvitys: Youtuben algoritmi antoi presidentinvaalien aikana näkyvyyttä oikeistolaisille ja erityisesti perussuomalaisille poliitikoille muiden kustannuksella
13.03.2024
Digivaalivahti

26.02.2024
Faktantarkistus
Työministeri Satosen väite Ruotsin parin tunnin poliittista lakoista ei pidä paikkaansa – oikeuskäytäntö ei tue väitettä
26.02.2024
Faktantarkistus
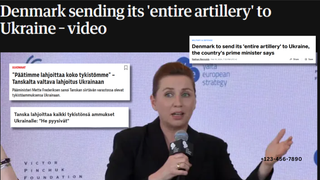
20.02.2024
Faktantarkistus
Tanska ei ole lahjoittamassa koko tykistöään tai kaikkia tykistöammuksiaan Ukrainaan
20.02.2024
Faktantarkistus

09.02.2024
Faktantarkistus
Stubbin A-studiossa esittämä väite tulitauon välittämisestä Georgiassa on vain osittain totta
09.02.2024
Faktantarkistus
EDU
Faktabaari EDU edistää kansalaisten digitaalista informaatiolukutaitoa - kykyä löytää ja tuottaa luotettavaa tietoa sekä säädellä omaa yksityisyyttään.
22.04.2024
FI
ITK-konferenssissa opettajia kiinnosti tekoäly – Faktabaari muistutti, että hyvässä autossa oltava hyvät jarrut
22.04.2024
FI
15.04.2024
FI
Faktabaari mukana ITK-konferenssissa – tutustu kattaukseen!
15.04.2024
FI

06.03.2024
FI
Luento: Propagandan historia ja vaikuttavuus
06.03.2024
FI

30.01.2024
EDU
Educa oli menestys, Uutisten viikko alkaa
30.01.2024
EDU
04.01.2024
EDU
Faktabaari mukana Tubecon Gamesissa
04.01.2024
EDU

19.12.2023
EDU
Digilukutaitopelit apuna opetuksessa
19.12.2023
EDU
