
Privacy is one of the most important fundamental rights in the digital age. It is based on national laws and European Union regulations such as the EU General Data Protection Regulation (GDPR) on the one hand, and international treaties and the UN Declaration of Human Rights on the other.
Privacy is primarily about the protection of private life, home and communications, but in the digital environment it is more appropriate to talk about the information relating to a specific person, i.e. personal data. This is the data that is stored on the digital devices and services we use, such as search engines and social media platforms. Such data is called a digital footprint.
To be a fully informed actor in the digital environment and to be able to manage your privacy in it, you need to know how the different devices and services used collect information about users. It is also important to be aware of the privacy concerns of other users, so as not to unintentionally infringe their privacy in the digital environment.
The digital footprint can be divided into active and passive digital footprints. An active digital footprint is information that a user has consciously added or otherwise generated on the web. Passive digital footprint is data collected by services without the user’s knowledge.
The distinction between active and passive digital footprints poses a problem, as awareness of data collection depends on the user’s knowledge. Nevertheless, it is a useful distinction to illustrate that often online and social media giants collect data without users’ knowledge or in a way that requires specific digital information literacy skills to become aware of it. This chapter therefore aims to provide a basic overview of the most common methods and techniques of data collection.
To whom is it safe to share your information?
Online services and applications usually require you to create a user ID, i.e. register. Before creating a new account and providing your personal information, it is worth checking that the company running the service or application appears to be trustworthy and that the information you provide is secure. This can be assessed by looking for additional information and reviews from other users.
There are several misleadingly named apps and games, which have been created based on popular apps and games. These counterfeited applications have been created with the sole purpose of extracting personal data from users. It is therefore worth checking to make sure that the author of the app is genuine and to read other users’ experiences. It is also advisable not to install apps from anywhere other than the official app stores. In the worst case, app downloads can contain malware and viruses that can steal information.
When registering the actual username, it is wise not to provide any information other than what is mandatory. You may also want to consider whether it is worth telling online services your real date of birth or your name. If this information is not explicitly required by the terms of use, it is not wrong to provide fictitious information. Registration forms can be deliberately designed to try to get the user to provide as much information about himself as possible, even if it is not necessary for the use of the service.
Any unique information such as name, telephone number, email address and home address may be used to search for information from other sources. It is good advice to use a secondary email address for registration.
For many online services, such as Google, Facebook and Apple, you can register using an existing user account. These are also unique pieces of information that usually allow the aggregation of information from elsewhere. If the service provider seems untrustworthy, it is better to be safe than sorry.
The use of online services and applications often generates personal and relevant content. Every post, like and comment accumulates data about us. In addition, social media services in particular allow us to communicate with other users. As a result, user accounts are frequently targeted by fraudsters and other cybercriminals. It is always a good idea to use two-way authentification when logging in, as this provides good protection against hacking attempts.
How do cookies work?
Online services and applications may store cookies, i.e. files containing information that they can use to track users, on users’ devices. The use and retention periods of cookies should always be explained on the service. In the case of cookies that are not necessary for the functioning of the service, the user’s consent must be obtained before cookies are used.
Examples of cookies that are essential are those used for logging in and for storing the choices made by the user. Non-essential cookies include cookies related to advertising, activity tracking and social media platforms. Non-essential cookies are typically related to the collection of data by various online services to gather information on users’ activities and interests, i.e. profiling.
For example, when a user logs on to Facebook, a cookie stores information about his or her username. When on Facebook, the cookie is necessary so that the user does not have to keep re-entering their ID and password. However, it is often overlooked that the cookie remains on the device even after logging out of Facebook, unless the user explicitly clears the cookie.
Many social and online services can embed functionality on other websites. For example, Facebook can embed a like button on a company’s website, a Facebook page embed or Facebook tracking pixels that allow users visiting the site to be targeted with Facebook ads. When a user visits such a site, the cookie previously stored on the device is automatically sent to Facebook when the embedded functionality is loaded from the Facebook server. The user does not need to be logged into Facebook at the same time if the cookie has been previously stored on the device. Facebook will be able to read the content of the cookie and identify the user based on that content. At the same time, Facebook will know which website the user is on.
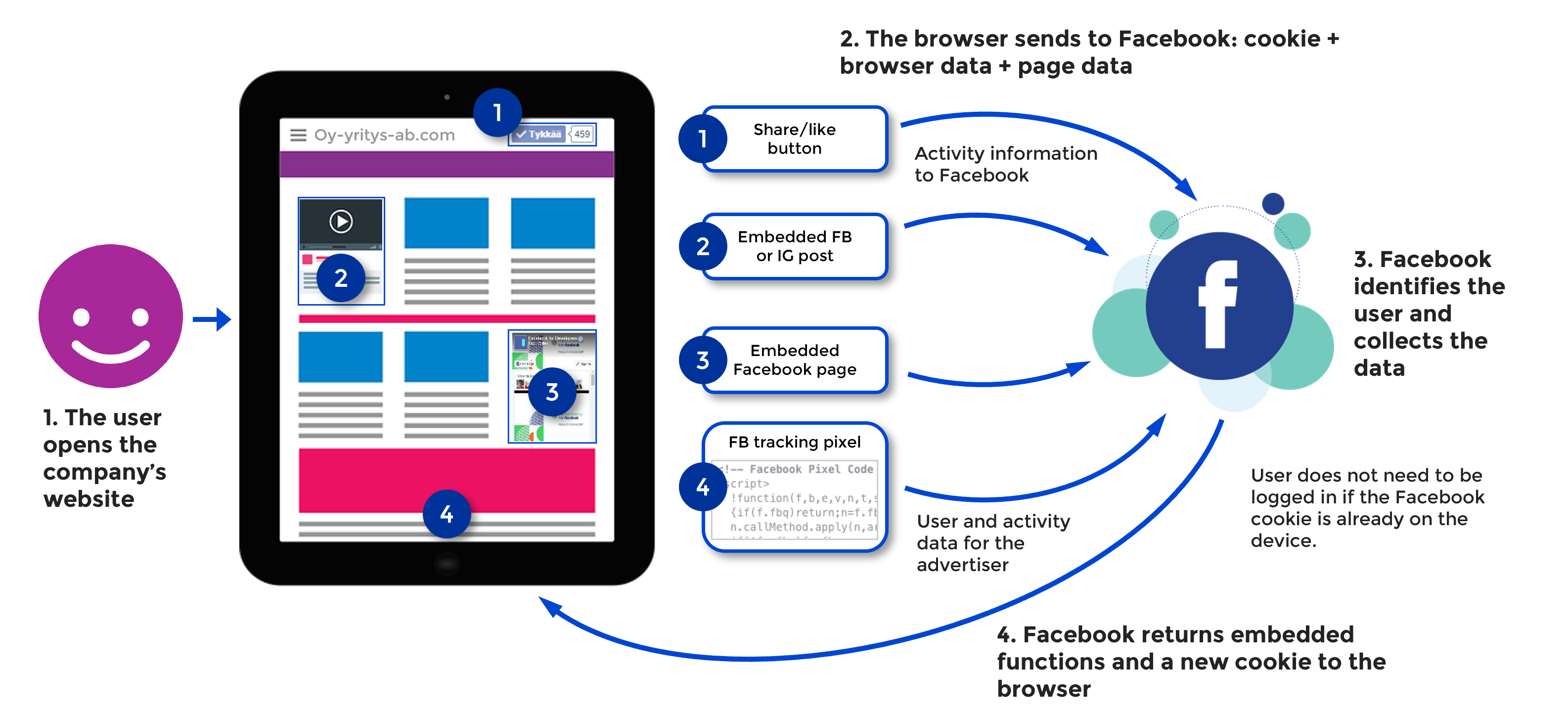
Facebook is able to continuously track user activity through cookies on millions of websites. In practice, this gives Facebook data on what users are interested in, what products they have recently viewed in online shops and so on. This data is used to target ads on the Facebook and Instagram ad platform.
Google and many other online companies also use cookies to profile users. A common use of cookies is so-called ‘remarketing’, where a user is shown an ad for the same product they have previously viewed in an online shop.
When visiting different websites, we now have to constantly respond to requests for permission to use cookies. It is worth remembering that only non-essential cookies are asked for, which are usually of no benefit to the user, but can be reasonably considered harmful and privacy-reducing. At worst, a single website can send data about a visit to dozens of data collection companies through cookies and other tracking functions. Online services in the EU must offer users the option to opt-out of non-essential cookies at the point of entry.
Cookies are not the only way in which online services can store trackable data on a user’s device. Another commonly used technology is local storage in the browser. Again, the service needs the user’s consent to use it. In addition, at least Google is developing a technology to replace cookies.
Is it worth sharing the location?
Online services and applications may ask users for permission to track their location. For example, a news site may give a reason to show the user a weather forecast based on their location, when in fact the location is also used to personalise content and ads.
In Google’s search engine and ad network ads, location tracking is used to infer user interests. Google explains the use of location as follows: ‘if you have enabled location tracking and frequently visit ski resorts, you may later see a ski ad in a YouTube video’. However, this use of location data to target ads can easily be avoided by not allowing Google apps to track your device’s location.
The GPS location of a device is not the only way to track users. More coarse, or less precise, localisation can be done, for example, using data from public Wi-Fi networks or the IP address of the user’s network connection. Even this type of location can be avoided by using a VPN to connect to the internet.
In addition to online services, many mobile phone applications request location access. It is worth assessing whether there are functions in the application where location is of real use and deciding whether to allow it to track your location. You should also check your phone settings to see which apps you have given location tracking permission to.
Device and browser identifiers
When online services and applications are used on different devices and web browsers, they can be assigned different unique identifiers. For example, Google and Apple have developed advertising identifiers for their advertising systems, which are used to identify users and target ads in mobile applications. The importance of these identifiers is that they can be used to link a specific device such as a mobile phone or tablet to a specific person in the same way as, for example, an email address, phone number or address.
Once an identity has been discovered through one application, it can then be identified in other applications used on the same device. There are numerous data businesses that aggregate and sell identity and user data to identify users.
Web browsers do not have the same unique advertising identifier system as mobile devices. This was not ‘necessary’ in the past because the use of cookies was very little regulated in the past and in many cases made it easy to identify the user.
As users have become more restrictive in their use of cookies, data collection companies have developed different browser identifiers. These tags are based on differences in browser configurations such as settings, installed fonts and browser plug-ins. They are called browser fingerprints, which describes well their purpose, i.e. to identify the user based on the browser they use. For example, the TikTok application is known to have used browser-specific image and audio tags in its web service, which can be used to identify the user even if he or she is not logged in to the service.
Don’t share your contact information with advertisers
When you use Instagram, Snapchat, TikTok or other apps, you may receive a request to allow your contact information to be used. Usually, the reason given for the request is that it would allow you to find and connect with your friends who use the app. However, it is not advisable to give permission, as the request will apply to all your contact information, and it may also be used for other purposes. So it’s worth making the effort to find the friends you want to contact through the app yourself.
Contact information is the same information that online and social media services use to target ads and content, as any other information they collect about you. It is network data that tells you who is connected to whom. Even if we do not share our contact information with social media services, they can know about our network of friends based on the contact information shared by others. For example, Facebook and Instagram can use it to suggest new friends and followers.
Sometimes contact information is used in unexpected situations. For example, Google says it uses contact information in its news recommendation algorithm. Most likely, Google assumes that we are interested in the same topics as our friends whose news reading is similar to ours.

Tracking in “dark” social media
Tracking interactions between users is easy for social media services as long as it happens on their own services. It’s clear that Instagram, for example, tracks which users’ posts we react to and uses the data it accumulates in its news feed algorithm.
In contrast, tracking user activity on applications outside of social media is more difficult for them. Increasingly, links to social media posts and news, for example, are shared on so-called dark social media, which refers primarily to messaging apps such as WhatsApp, Snapchat and Yodel.
Normally, the web service provider has no way of knowing who has shared the link outside the service and to whom. However, many online and social services have developed techniques to attach identifiers to links, which allow them to know who originally shared the link. These tags can, for example, be in the form of a # code following the actual link address or so-called shortened links. A number of link aggregation services allow link sharing to be tracked.
When a shared link is opened, web services know who shared the link from its tag. In addition, web services can often identify the users who have opened the link, for example by using cookies or other means described above. As a result, they will also gain information about link sharing via the ‘dark’ social media and about the networks between users.
How can data be deleted?
The easiest way to delete data accumulated on online services and applications is to simply delete the publications you have made, clear the location or browsing history stored in the service, delete the contact information you have transferred or delete your entire user account. Usually, the terms of use include a condition that if a user deletes his data, the service provider is not allowed to keep it afterwards.
Many online services and applications allow you to control what information it stores about your activities and how it is used. These options can be found in the settings of the user account. For example, the Google user account settings allow you to opt out of personalisation of ads, so that the data stored in your account is not used to target ads.

Harto Pönkä (M.Ed.) has a broad background in e-learning pedagogy, media education, social media and data protection. He has been a trainer since 2008 and has published books and articles on social media. Pönkä provides training and analysis for companies, associations and public administrations. Pönkä works for his companies Innowise and Tweeps.
Artwork: Lumi Pönkä
Download the Digital Information Literacy Guide (PDF).
