
Generative AI (GenAI) uses Large Language Models (LLMs) and neural networks. It is a branch of AI that creates new content rather than simply analysing or classifying existing content or data.
The following definition of generative AI is derived from the Finnish National Agency for Education’s version of the draft statement [i]:
Generative AI refers to AI applications that can generate new content, such as text, images and videos. They are often based on machine learning and large-scale training data. Machine learning applications can learn new content from data. One form of generative AI is Large Language Models (LLM), which are used to generate and process human-like language.
While natural language is a common way to interact with GenAI, it is not the only way to interact with GenAI; inputs can also be, for example, code or images. GenAI generates new content based on a model created from training materials. Large language models can be generated either from public content on the Internet or from more limited, closed data sets.
In addition to large language models, generative AI can also be based on other models and techniques optimised for specific purposes, such as creating new music, videos or images. For example, so-called diffusion models focus on the creation and manipulation of images and sound.
Large language models
Large language models are trained on huge amounts of data. This data can include books, articles, code and other forms of written communication, as well as images and graphics.
Continuous data collection is made possible by data collectors – bots that collect data from the web. Nowadays, website operators can also opt out of data collection. It should be noted that data collection can also lead to the accumulation of inaccurate, discriminatory and biased information in training materials.
Language models use the collected data to learn the relationships between words and phrases and the meanings of different types of text. This enables them to perform a variety of tasks, such as translating languages, producing creative content and answering questions. As AI technology develops, these models will become more sophisticated and offer opportunities for a wide range of applications.
Chatbots and virtual assistants use language models to provide users with responses to their input. Content creators use these models to produce articles, blog posts and marketing materials. In education, for example, they help teachers to create teaching materials and exercises.
Language models are built using neural networks, particularly the so-called transformer architecture. It is a deep learning method that provides an efficient way of processing e.g. sentences, text fragments and contexts. To make this possible, the text needs to be transformed into a numerical format that allows complex computations. This is called tokenisation.
Language models are built using neural networks
Data points and tokens
Tokenisation is the process of converting text or images into a numerical format that computers can process. It involves breaking text into smaller pieces called tokens, which can be words, phrases or even single characters. Each token is given a numerical representation (embedding) that reflects its meaning in context. This method allows mathematical operations between sequences of words (tokens), for example by comparing their similarity. Contextualisation, which considers the occurrence of a sequence of words in the surrounding text, is crucial for the model to understand the meaning of a sentence or paragraph.
By breaking down text into tokens, models can better understand the underlying structure and meaning of the language.
Tokenisation splits the text into parts. Numerical representation (embedding) turns words into numbers (vectors). Contextualisation changes these vectors to reflect the meaning of the word in the context in which it occurs. This allows the computer to “understand” that the same word can mean different things in different sentences. The vectors can also be used to calculate the similarity of words: vectors that are close together mean similar things.
A data point represents a single observation or event in a data set. A token is a smaller, indivisible unit of data extracted from a data point. In the sentence “The cat sat on the mat”, each word (“the”, “cat”, “sat”, “on”, “the”, “mat”) would be considered a token. However, tokenisation can be more nuanced. For example, the word “running” could be broken down into subword tokens such as “run” and “ing”. This approach, known as subword tokenisation, helps models deal with rare words or words that are not in their vocabulary.
Data points and tokens are the basic data units used to train and operate AI systems.
For example, a data point can be thought of as a complete recipe that lists all the ingredients, while a token can be thought of as a single ingredient in that recipe.
AI models work by processing many data points, each containing multiple tokens. The model analyses the relationships between these tokens to learn patterns and make predictions.
Tokens, data points and models are used to produce output. For example, GenAI tools can be asked to answer a question in the form of a text prompt that serves as input to a statistical model. The statistical model converts this prompt into numbers. The model then performs computations to predict the output based on statistical associations.
The best-known generative AI service is called ChatGPT, where GPT stands for “Generative Pre-trained Transformer”, which refers to the way ChatGPT is trained to process and understand large amounts of text data. This pre-training enables ChatGPT to produce human-like text in response to a variety of questions and requests. The model is a “transformer” because it uses a powerful neural network architecture.
The Financial Times has made an excellent visual story about how the transformer works. [ii]
What material has been used to train language models?
According to OpenAI [iii], the models used by the current ChatGPT have been developed using three primary sources of information:
- Information that is publicly available on the Internet,
- Information that we partner with third parties to access, and
- Information that our users or human trainers and researchers provide or generate.
Unfortunately, however, these massive data sets often lack clear information about what they contain and where they come from [iv]. AI companies generally do not disclose what data they have used to train their models. One reason is that they want to protect their own competitive advantage. Another reason is that because data sets are bundled, packaged and distributed in a complex and opaque way, they are unlikely to know where all the data comes from.
The data used to train AI models is also heavily Western. More than 90% of the data sets analysed by the researchers came from Europe and North America, and less than 4% from Africa [v]. The dominance of English in the training data is partly explained by the fact that the Internet is still more than 90% English-speaking, and there are still many places on the planet where Internet connectivity is very poor or non-existent. This bias in the training material also has an impact on AI’s performance and should always be viewed with a healthy dose of scepticism.
Holmes and Tuomi [vi] stress that the role of humans in the functioning of AI systems should not be forgotten. Humans collect or curate the training data (e.g. images or text) used by AI, and humans write the algorithms or programme code underlying AI technologies and decide what to do with it.
The data used to train AI models is heavily Western.
Pre-training and neural network
During pre-training, the algorithms process a huge number of data points and tokens based on a large data mass.
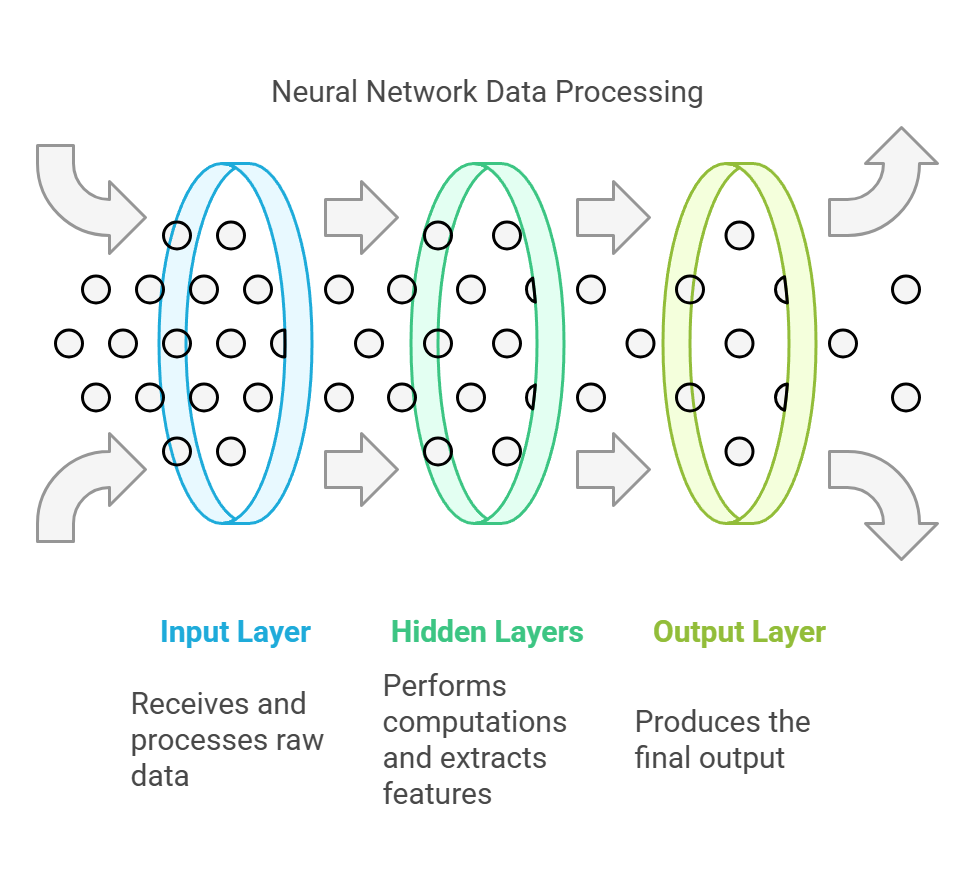
A key element of generative AI is a neural network that mimics the general principles of neuronal function in the animal brain. A neural network is composed of interconnected nodes arranged in layers.
- Input layer – receives and processes the raw data (e.g. an image, text or numerical values).
- Hidden layers – perform complex computations on the input data, extracting features and identifying patterns.
- Output layer – produces the network’s output, which can take various forms.
Neural networks are made up of interconnected nodes, arranged in layers.
Made with Napkin
During training, the AI model learns the relationships and patterns within the data by adjusting the strength of the connections between nodes, called weights. The training process involves continually adjusting these weights to minimise errors and improve the model’s ability to predict or generate content. Optimisation algorithms are commonly used to adjust the weights, the most important of which is currently the “GTP”, after which ChatGPT is named.
Once the AI model has been sufficiently trained, it is able to generate content based on the given input. Based on the patterns and relationships it learns from the training data, the model produces a consistent and contextually appropriate output for the training data that was used.
Generative AI utilises deep learning models, which are part of machine learning models. Machine learning refers to the ability of a system to learn autonomously from the data it is given, without a human determining all its functions. Deep learning allows AI models to learn to recognise patterns and connections in massive amounts of data, such as images or text. They can then generate new, similar data that replicates the features present in the original data. This differs from traditional rule-based AI systems, which follow predefined rules and are unable to learn or improve over time.
Training AI models requires huge amounts of data, high-performance technology and financial resources. Only very large companies can develop these models. Fortunately, these models can be used for many different purposes.
Although generative models are powerful, they also have limitations. For example, they can produce erroneous conclusions and biased content.
Training AI models requires huge amounts of data, high-performance technology and financial resources.
Fine-tuning
Fine-tuning aims to adapt a foundational model to a specific task. The model is trained on a smaller and limited set of data related to the desired application. Fine-tuning improves the performance of the model in the given task domain and makes the model more cost-effective to use.
Fine-tuning enables the development of GenAI applications for a wide range of purposes. Indeed, dozens of new AI applications are appearing on the market every week for a wide variety of purposes.
Input, prompt or feed
An Input is a command given by the user to the AI. It can be text, sound, image or programme code. Based on the input, the AI produces the desired result. The more precise and detailed the input, the better the result.
It is the inputs that influence the outcome produced by the generative AI. Skilful design of inputs is therefore an important skill to practice. Fortunately, there are many instructions and examples available on the Internet, and many AI services also provide tools and example feeds. You can also ask AI services directly for advice on how to create a better feed. In most cases, it is not a good idea to settle for the first result, but to work on it further by asking the AI service to refine and improve the output.
The difference between generative AI services and search engines
It is very important to recognise that “traditional” search engines and generative AI software serve different needs and provide different services to their users. Search engines search for existing information, while GenAI services create new content.
Search engines use algorithms that analyse page content, number of links and other factors to determine the relevance and order of pages in search results. They search and organise data on the Internet based on the search terms entered by the user.
Search results are based on both the user’s previous searches and the recommendations of the search engine’s algorithm.
In most cases, the information seeker will receive thousands or even millions of direct links to data on the Internet. It is the user’s responsibility to choose the one that best suits their information needs. On the positive side, the user can directly assess the reliability of the information source. Unfortunately, search engines such as Google do not use transparent search logic, and organise and censor results based on the user’s profile. Paid or sponsored results often come first in search results, as search engines are driven by commercial interests.
More recently, GenAI services have started to propose a combination of these two different approaches. For example, Google Gemini (version 1.5 Flash) offers the possibility to “check” GenAI results with the Google search engine. This function can be found in the three-dot menu below the answer (“Check the answer carefully”).
If you use a “normal” search engine to find information on, say, Faktabaari, you will be presented with millions of very different results (Bing: over 15 million hits), including criticisms of Faktabaari. Asking ChatGPT’s online search function “What is Faktabaari” will return a short summary of Faktabaari. One may wonder why particular sentences are chosen and whether the ChatGPT summary gives a realistic and comprehensive picture of Faktabaari’s activities.
The operating mechanism of generative AI applications creates new content from large amounts of data. The user usually receives only one answer at a time, based on computed probabilities according to the process described above. On the other hand, the user can receive additional information by submitting finetuning questions and prompts and the results can be further processed and refined. Although the answer produced by the GenAI service often has a high degree of confidence, it may be incorrect. GenAI models do not understand the text they produce but are based on statistical models and training data. Therefore, their outputs may be incorrect or misleading. This highlights the need for source criticism when checking the outputs of GenAI services. So, for example, under the Gemini input field it says “Gemini can make mistakes, even when it comes to information about people, so it’s important to double-check its responses.”
Although the answer provided by the GenAI service is often very reliable, it may be incorrect.
Useful links
How Chatbots and Large Language Models Work video https://youtu.be/X-AWdfSFCHQ
Read the entire AI Guide for Teachers here.
Sources
[i] Tekoäly varhaiskasvatuksessa ja koulutuksessa – lainsäädäntö ja suositukset (ladattu 17.10.2024 lausuntopalvelu.fi) https://www.lausuntopalvelu.fi/FI/Proposal/Participation?proposalId=a0d6af03-67e1-4ec7-9269-fab75bb05807
[ii] Generative AI exists because of the transformert (uploaded 18.1.2025) FT. https://ig.ft.com/generative-ai/
[iii] OpenAI (Haettu 13.12.2024) https://help.openai.com/en/articles/7842364-how-chatgpt-and-our-foundation-models-are-developed
[iv] MIT Techonology Review (Haettu 18.12.2024) https://www.technologyreview.com/2024/12/18/1108796/this-is-where-the-data-to-build-ai-comes-from/
[v] MIT Techonology Review (read 18.12.2024) https://www.technologyreview.com/2024/12/18/1108796/this-is-where-the-data-to-build-ai-comes-from/
[vi] Holmes, Wayne and Tuomi, Ilkka (2022) State of the art and practice in AI in education. Speciali Issue: Futures of artifical intelligence in education. European Journal of Education. Volume 57, Issue 4. https://onlinelibrary.wiley.com/doi/10.1111/ejed.12533
Read the entire AI Guide for Teachers here.
