
Generativ artificiell intelligens (GenAI) baserar sig på stora språkmodeller (large language models) och neurala nätverk. Det handlar om en typ av artificiell intelligens, som producerar nytt innehåll istället för att bara analysera eller kategorisera befintligt innehåll eller befintliga data.
Följande definition av generativ artificiell intelligens är en bearbetad version av definitionen som ingår i Utbildningsstyrelsens AI-rekommendationer, som sänts på remiss [i]:
Med generativ artificiell intelligens (AI) avses AI-verktyg som kan producera nytt innehåll, till exempel texter, bilder och videor. Verktygen bygger ofta på maskininlärning och en stor mängd träningsdata. Utifrån träningsdata kan maskininlärningsbaserade verktyg lära sig nytt innehåll. En form av generativ AI utgörs av de så kallade stora språkmodellerna (large language models), som används för att producera och bearbeta naturligt språk som liknar människans språk.
Även om det är vanligt att interagera med GenAI på naturligt språk, är dess funktionalitet inte begränsad till det utan promptarna kan också bestå till exempel av kod eller bilder. GenAI producerar nytt innehåll med hjälp av en modell som skapats utifrån träningsdata. De stora språkmodellerna har byggts upp med antingen offentligt tillgängligt innehåll på internet eller med mer begränsade, slutna datamängder.
Utöver stora språkmodeller kan generativ AI också bygga på andra typer av modeller och tekniker, som är optimerade för specifika ändamål, såsom för att skapa ny musik, videor eller bilder. Till exempel har de så kallade diffusionsmodellerna fokus på att skapa och redigera bilder och ljud.
Stora språkmodeller
Stora språkmodeller tränas med stora mängder data. Dessa data kan bestå av böcker, artiklar, kod eller andra former av skriftlig kommunikation samt av bilder och grafik.
Datainsamling kan göras kontinuerligt på nätet tack vare så kallade datainsamlare. Nuförtiden kan de webbansvariga förhindra (eng. ’opt-out’) datainsamling på sina webbplatser. Det är bra att komma ihåg att träningsdata som samlas in också kan innehålla en stor mängd felaktig, diskriminerande och fördomsfull information.
Chattbotar och virtuella assistenter använder sig av språkmodeller för att producera svar utifrån användarnas promptar. Innehållsproducenter dra också nytta av dessa modeller för att skriva artiklar, bloggtexter och marknadsföringsmaterial. Inom utbildningssektorn hjälper modellerna lärare att skapa till exempel undervisningsmaterial och övningsuppgifter.
Språkmodellerna använder det insamlade materialet för att lära sig relationerna mellan ord och satser samt innebörden i olika typer av texter. På så sätt kan de utföra olika typer av uppgifter, såsom översätta språk, producera kreativt innehåll och svara på frågor. I takt med att AI-tekniken utvecklas kommer dessa modeller att utvecklas ytterligare och möjliggöra tillämpningar på ännu flera områden.
Språkmodellerna byggs upp med hjälp av neurala nätverk och speciellt den så kallade transformatorarkitekturen. Det är en metod baserad på djupinlärning som möjliggör ett effektivt sätt att bearbeta till exempel meningar, textavsnitt och kontexter. För att det ska vara möjligt måste texten konverteras till ett numeriskt format, vilket möjliggör komplexa matematiska beräkningar. Detta kallas för tokenisering.
Datapunkter och tokens dvs. teckensträngar
Tokenisering är en process, där text eller bilder omvandlas till ett numeriskt format, så att de kan hanteras av datorer. Under processen spjälkas en text upp i mindre delar, tokens, som kan bestå av ord, orddelar eller till och med enskilda tecken. Varje token ges en numerisk representation vid inbäddning (eng. ’embedding’), som återspeglar dess betydelse i den aktuella kontexten. Metoden möjliggör matematikbaserade operationer mellan olika ordsekvenser (tokens), till exempel i form av jämförelser av hur lika sekvenserna är. För att modellen ska kunna förstå innebörden i en mening eller ett textstycke är det viktigt med kontextualisering, som tar hänsyn till den textuella kontexten som ordsekvensen förekommer i.
Exempel (skapat med Gemini 2.0 Flash Experimental)
Vid tokenisering spjälkas texten upp i mindre delar. Vid inbäddning (eng. ’embedding’) omvandlas orden till siffror (vektorer). Kontextualiseringen ändrar vektorerna så att de återspeglar ordets betydelse i den aktuella kontexten. På så sätt kan datorn “förstå” att samma ord kan betyda olika saker i olika meningar. Med hjälp av vektorerna kan man också beräkna hur lika olika ord är: vektorerna som ligger nära varandra är också betydelsemässigt lika.
Ordet “bok”.
- Betydelse 1: Träd (lövträd)
- Betydelse 2: Längre skrift
Meningar:
- “Intill brunnen på gården stod en stor bok.” (träd)
- “Jag har läst en spännande bok.” (längre skrift)
Tokenisering:
I båda meningarna har odet “bok” tokeniserats.
Kontextualisering:
- Mening 1 (“Intill brunnen på gården stod en stor bok.”): Kontexten “på gården” tyder på något som finns utomhus.
- Mening 2 (“Jag har läst en spännande bok.”): Kontexten “läst” och “spännande” syftar på en skrift och en läsupplevelse.
Numerisk representation (inbäddning, embedding) med kontexterna:
Vid kontextualisering skapas olika vektorer för ordet “bok” i olika meningar:
- “bok” (träd, mening 1): [0.1, 0.9] (Den här vektorn ligger närmare vektorer för andra träd, t.ex. “tall”, “björk”.)
- “bok” (skrift, mening 2): [0.9, 0.1] (Den här vektorn ligger närmare vektorer för andra kulturupplevelser, t.ex. “film”, “podcast”.)
Vektorerna skiljer sig nu tydligt från varandra. Det här visar att ordet har olika betydelser beroende på kontext.
En datapunkt utgörs av en enskild observation eller förekomst i en datamängd. En token är en mindre, odelbar enhet, som har identifierats i en datapunkt. En token kan också vara en orddel (t.ex. kan ordet “apparat” delas upp i följande tokens: “ap”, “par”, “at”). En token är en grundläggande byggsten som används för att framställa och bearbeta data i en AI-modell. Datapunkter och tokens är grundläggande dataenheter, som är centrala för träning och användning av AI-system.
En datapunkt kan ses till exempel som ett komplett recept med en lista över alla ingredienser, medan en token snarare motsvarar en enskild ingrediens i receptet.
AI-modellerna fungerar så att de går igenom flera datapunkter, som alla innehåller ett flertal tokens. AI-modellen analyserar relationerna mellan dessa tokens för att lära sig mallar och göra förutsägelser.
Tokens, datapunkter och mallar används för att producera ett svar utifrån en prompt. Man kan till exempel ställa en fråga till ett GenAI-verktyg i form av en textprompt, som i sin tur utgör indata för en statistisk modell. Den statistiska modellen omvandlar prompten till siffror. Därefter utför modellen beräkningar för att producera ett resultat utifrån statistiska samband.
Det mest kända generativa AI-verktyget heter ChatGPT, där förkortningen GPT står för “generative pre-trained transformer” (‘generativ förtränad transformator’), vilket syftar på metoden som använts för att träna ChatGPT så att den kan hantera och förstå stora mängder textdata. Tack vare träningen kan ChatGPT ge svar på olika frågor och förfrågningar, som liknar människoproducerade svar. Modellen är som en “transformator” (eng. ‘transformer’), eftersom den använder sig av en kraftfull arkitektur bestående av neurala nätverk.
Vilket material används för att träna språkmodellerna?
Enligt OpenAI [ii] har de nuvarande modellerna som används av ChatGPT utvecklats med hjälp av tre huvudsakliga datakällor:
- information som är allmänt tillgänglig på internet
- information som OpenAI får tillgång till tack vare samarbetet med tredje part
- information som användarna eller tränarna och forskarna tillhandahåller eller producerar.
Tyvärr saknar dessa enorma datamängder ofta tydlig information om vad de innehåller och var de kommer ifrån. AI-företag berättar oftast inte vilka data de har använt för att träna sina modeller [iii]. En orsak till det är att de vill skydda sin egen konkurrensfördel. En annan orsak är att de förmodligen inte heller själva vet var alla data kommer ifrån, eftersom datamängder slås ihop, paketeras och distribueras på ett komplext och ogenomskinligt sätt.
De data som används för att träna AI-modeller har också starkt fokus på den västerländska sfären: mer än 90 procent av de datamängder som analyserats av forskare härstammar från Europa och Nordamerika och mindre än 4 procent från Afrika [iv]. Det engelska språkets dominans i träningsmaterialet förklaras delvis av att internet fortfarande till över 90 procent fungerar på engelska och att det fortfarande finns många platser i världen där internetanslutningar är mycket dåliga eller icke-existerande. Ett så ensidigt träningsmaterial har också en inverkan på det som AI kan genereras, och därför är det alltid förnuftigt att förhålla sig kritisk till det.
Holmes och Tuomi [v] understryker att man inte får glömma människans roll i hur AI-system fungerar. Det är människor som samlar in eller sammanställer träningsdata (t.ex. bilder eller texter), som sedan används av AI, och det är människor som skriver algoritmerna, dvs. programkoden, bakom AI-tekniken och bestämmer vad de ska användas till.
Förträning och neurala nätverk
Under förträningen (eng. ‘pre-training’) går algoritmerna igenom en enorm mängd datapunkter och tokens utgående från en omfattande datamassa.
Ett viktigt element i generativ AI utgörs av ett neuralt nätverk, som efterliknar de allmänna principerna för hur nervcellerna i en djurhjärna fungerar. Neurala nätverk består av sammankopplade noder ordnade i lager.
Inmatningslagret tar emot data, som därefter passerar genom ett antal dolda lager, där det utförs olika beräkningar. Det sista lagret, utmatningslagret, producerar det slutliga resultatet. 
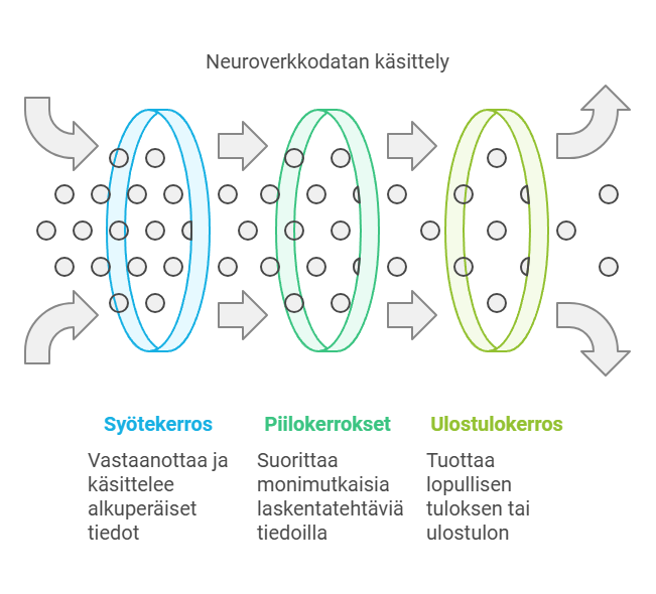
I samband med träningen lär sig AI-modellen de interna relationerna och formlerna i de aktuella data genom att justera styrkorna hos kopplingarna mellan noderna. Detta kallas för viktning. Det är en del av träningsprocessen att viktningarna ständigt justeras, så att det ska vara möjligt att minimera mängden fel och så att modellen allt bättre ska kunna göra förutsägelser och skapa innehåll. För justering av viktningar används i allmänhet optimeringsalgoritmer, varav den viktigaste för närvarande är “GTP”, som ChatGTP också döpts efter.
När AI-modellen har tränats tillräckligt kommer den att kunna producera innehåll utgående från prompten den får. Utifrån formlerna och kopplingarna modellen lärt sig tack vare träningsdata klarar den av att producera svar som är logiska och kontextuellt korrekta i ljuset av data den tränats med.
Generativ AI använder sig av modeller för djupinlärning, som är en typ av modeller för maskininlärning. Med maskininlärning avses att ett system på egen hand kan lära sig av de data som det matas med, utan att en människa bestämmer över alla dess funktioner. Med hjälp av djupinlärning kan AI-modellerna lära sig att identifiera mönster och kopplingar i enorma mängder data, som består av till exempel bilder eller texter. Därefter kan de producera nya, likartade data, som har samma egenskaper som originaldata. På så sätt skiljer de sig från traditionella regelbaserade AI-system, som följer vissa förutbestämda regler och som inte klarar av att lära sig eller bli bättre över tid.
För att träna AI-modeller behövs det enorma mängder data, teknik med hög prestanda och ekonomiska resurser. Endast mycket stora företag har möjlighet att utveckla sådana modeller. Som tur är kan dessa modeller användas för en mängd olika ändamål.
Även om generativa modeller är effektiva har de också begränsningar. De kan till exempel producera felaktiga slutsatser och snedvridna resultat (AI-bias).
Finjustering
Syftet med finjustering (eng. ‘fine-tuning’) är att anpassa grundmodellen (eng. ’foundational model’) till en specifik uppgift. Modellen tränas då med en mindre, avgränsad datamängd, som berör det önskade användningsområdet. Finjusteringen förbättrar modellens prestanda på användningsområdet i fråga och gör modellen mer kostnadseffektiv.
Tack vare finjusteringen kan GenAI-verktyg utvecklas för ett brett spektrum av olika ändamål. På marknaden har det därför också dykt upp dussintals nya AI-verktyg, det ena märkligare än det andra.
Promptar eller instruktioner för AI
En prompt (input) är en order som användaren ger ett AI-verktyg. Det kan bestå av text, ljud, bild eller programkod. Utifrån prompten producerar AI-verktyget det önskade resultatet. Ju mer exakt och detaljerad prompten är, desto bättre blir oftast också resultatet. År 2024 anges det vanligtvis i en prompt tydligt vilken roll AI ska ha, vad man önskar för slutresultat och vilka instruktioner AI-verktyget behöver ha. Till exempel: “Sammanställ en lista över presidenterna under Finlands självständighet.”
Svaret som generativ AI producerar är helt beroende av promptarna. Konsten att formulera effektiva promptar är därför en viktig färdighet som det är bra att öva på. Som tur är finns det gott om instruktioner och exempel på internet, och många AI-tjänster erbjuder också verktyg för det samt exempelpromptar. Det är också möjligt att direkt be AI-tjänster om instruktioner för hur man formulerar bättre promptar. Oftast gör man klokt i att inte lita på det första svaret ett AI-verktyg ger, utan det är bra att jobba vidare på det genom att be AI-verktyget att precisera och förbättra svaret.
Generativa AI-verktyg och sökmotorer är fundamentalt olika
Det är mycket viktigt att vara medveten om att “traditionella” sökmotorer och generativa AI-verktyg tillgodoser olika behov och tillhandahåller olika tjänster åt sina användare. Sökmotorerna söker efter befintlig information, medan GenAI-tjänster skapar nytt innehåll.
Sökmotorerna använder sig av algoritmer som analyserar innehållet i, antalet länkar på och andra egenskaper hos webbplatser, för att bestämma hur relevanta de är för och i vilken ordning de ska visas i sökresultaten. De söker efter och organiserar data på internet utifrån de sökord användaren ger. Sökträffarna är baserade på både användarens tidigare sökningar och rekommendationerna från sökmotoralgoritmen.
Den som gör sökningen får sedan oftast tusentals eller till och med miljontals direkta länkar till material på internet. Det är på användarens ansvar att välja ut den sökträffen som bäst motsvarar det hen varit ute efter. Fördelen är att användaren själv direkt kan bedöma informationskällornas tillförlitlighet. Tyvärr är logiken bakom sökningarna i sökmotorerna, såsom Google, inte transparent, och de ordnar och censurerar sökträffar med hjälp av användarprofilering. De första sökträffarna brukar vara betalda eller sponsrade träffar, eftersom sökmotorerna drivs av kommersiella intressen.
Alldeles nyligen har GenAI-tjänsterna börjat föreslå en kombination av dessa två olika tillvägagångssätt. Till exempel erbjuder Google Gemini (version 1.5 Flash) möjligheten att “kontrollera” svaret GenAI producerat med Googles sökmotor. Man kommer åt funktionen i menyn bakom tre prickar under själva svaret (“Dubbelkolla svaret”).
Om man söker information om till exempel Faktabaari med en “vanlig” sökmotor dyker det upp hundratals eller tusentals sinsemellan väldigt olika träffar, däribland kritik om Faktabaari. Frågar man ChatGPT:s webbsökningsfunktion vad Faktabaari är får man läsa en kort sammanfattande text om Faktabaari. Man kan fråga sig varför just dessa meningar har valts ut för sammanfattningen och huruvida de ger en realistisk och heltäckande bild av Faktabaari. Skulle det med tanke på medborgarnas tillgång till information kanske ändå vara bättre att få en mer nyanserad bild av Faktabaari?
Funktionsmekanismen för generativa AI-verktyg är dock en annan. De skapar nytt innehåll utgående från stora datamängder. Användaren får vanligtvis bara ett svar i taget, som baserar sig på sannolikhetsberäkningar i enlighet med processen som beskrivits ovan. Å andra sidan kan användaren be om och få till exempel hundratals svar och sedan jobba vidare på och precisera resultaten. Även om de svar som GenAI-tjänster producerar ofta ger ett mycket tillförlitligt intryck kan de vara felaktiga. GenAI-modellerna kan inte själva förstå den text de producerar, utan de baserar sig på statistiska modeller och träningsdata. Därför kan resultaten de producerar vara felaktiga eller vilseledande. Därför är det speciellt viktigt att granska resultaten GenAI producerar med källkritiska ögon. Därför står det också under promptfältet i Google Gemini så här: “Gemini kan göra fel, också när det gäller människor. Du bör alltså kontrollera alla svar du får.”
Användbara länkar
How Chatbots and Large Language Models Works-video https://youtu.be/X-AWdfSFCHQ
Santeri Kallio (2024): Mitä on generatiivinen tekoäly – GenAI-opas https://santerikallio.com/genai-opas/
Ylen oppiminen: Älyä tekoälyä. Lärarens verktygslåda för undervisning (på finska) – https://yle.fi/a/74-20069158
Källor
[i] Artificiell intelligens inom småbarnspedagogik och utbildning – lagstiftning och rekommendationer (hämtad 17.10.2024, lausuntopalvelu.fi) https://www.lausuntopalvelu.fi/SV/Proposal/Participation?proposalId=a0d6af03-67e1-4ec7-9269-fab75bb05807
[ii] OpenAI (hämtad 13.12.2024) https://help.openai.com/en/articles/7842364-how-chatgpt-and-our-foundation-models-are-developed
[iii] MIT Techonology Review (hämtad 18.12.2024) https://www.technologyreview.com/2024/12/18/1108796/this-is-where-the-data-to-build-ai-comes-from/
[iv] MIT Techonology Review (hämtad 18.12.2024) https://www.technologyreview.com/2024/12/18/1108796/this-is-where-the-data-to-build-ai-comes-from/
[v] Holmes, Wayne och Tuomi, Ilkka (2022): State of the art and practice in AI in education. Speciali Issue: Futures of artifical intelligence in education. European Journal of Education. Volume 57, Issue 4. https://onlinelibrary.wiley.com/doi/10.1111/ejed.12533
- Läs guiden kapitel för kapitel på vår webbplats – tack vare Svenska folkskolans vänner rf också på svenska
